Do you seek to optimize your business operations, cut costs, and improve efficiency? The single solution for all of your requirements can be to outsource your back office support. Let’s delve into the advantages of outsourcing back office support to vendor partners.
Table of Contents
Back Office Support and its Significance
Before understanding the benefits of outsourcing, let’s check out what back office support entails. Back office support refers to the administrative and procedural tasks essential for a business’s smooth operations; however, they do not contribute directly to revenue generation. Back office tasks include bookkeeping, data entry, human resource management, inventory management, payroll processing, and the like.
Advantages of Back Office Support Outsourcing
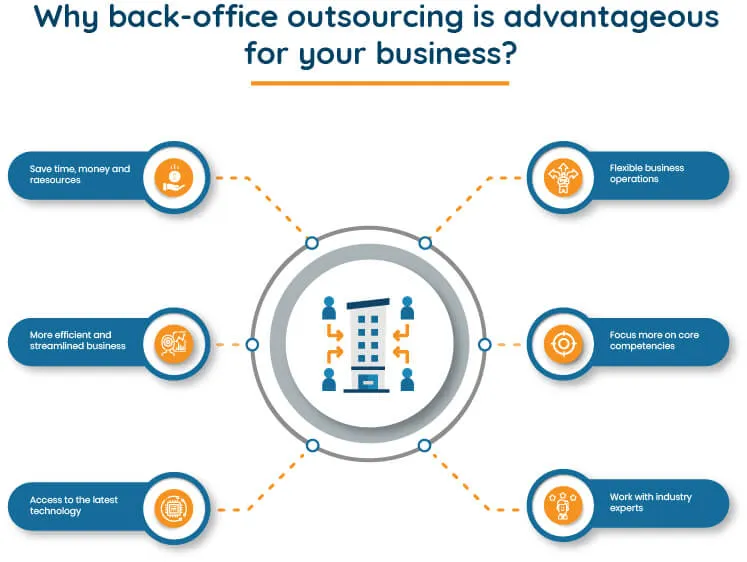
1. Cost Cutting
For any business, the prime objective is to generate revenue, and hiring external back office support services will significantly improve your bottom line. By choosing to outsource, you can avoid the costs associated with hiring, training, providing benefits, and maintaining office space and equipment for in-house staff. External vendors are generally based in areas with lower labor costs. They are thus able to offer a skilled labor pool at reasonable pricing.
2. Readymade Expertise
Generally, back office support providers are used to working with businesses across verticals. They ensure that their staff undergo regular training to stay up-to-date with the latest technologies and best practices. Outsourcing enables you to get this readymade specialized expertise at a bargain.
3. Free to Focus on Core Activities
Your execution of core business activities would set you apart from the competition. Outsourcing your back office support to a reliable vendor frees you to focus on your core activities. With your back office tasks being executed by a bankable partner, you can devote more resources in the form of time and effort to your company’s primary objectives and important activities.
4. Flexibility and Scalability
Today’s business world is dynamic, and you need solutions that can adapt to the ever-changing demands of your clientele. Outsourcing back office support facilitates flexibility and scalability as your outsourced partners can promptly allocate or deallocate resources to meet your requirements. It especially provides an edge to startups and small businesses that usually tend to experience unpredictable growth patterns.
5. Improved Efficiency and Productivity
You can outsource your back office support to vendors that are equipped with cutting-edge technology, apt know-how, and efficient processes. Hence, it allows them to handle the delegated tasks as per your instructions and requirement. With minimized errors and improved turnaround times, you will notice increased overall productivity, compared to handling all back office operations in-house.
6. Compliance Management and Reduced Risk
Some specialized tasks, such as tax reporting, insurance back office services, and payroll processing, involve complex regulations and legal requirements. You can reduce the risk of non-compliance with changing regulations and rules by outsourcing these tasks to experienced service providers. Thus, you would no longer need to worry about paying heavy penalties for non-compliance or regulatory issues.
7. 24/7 Support
Whether or not you are a global player, your customers expect customer service 24/7. You can pick an outsourcing partner that can offer back office support round the clock. That would enhance customer satisfaction and ensure that you gain a competitive edge.
8. Streamlined Operations
To start outsourcing, you might have to adopt standardized processes and practices. By doing so you can streamline your operations across various aspects of the business. Linear and consistent operations ultimately lead to improved overall performance.
9. Zero In on Core Competencies
Expertise makes your businesses special. When you outsource non-core activities, such as back support, you can free up resources to focus on your core competencies. This helps you channel your resources wisely for critical tasks like customer engagement, product development, and strategic planning. This would eventually result in improved customer satisfaction and better brand recognition.
10. Time Savings
With back office tasks off your plate, your team would have more time to dedicate to important tasks that require their expertise. Thus, this would gradually foster creativity, innovation, and a more fulfilling work environment for your team.
Conclusion
Any business, big or small, will have its own back office operations. Depending on the scale of work, sometimes it can be handled within the organization. But often, businesses can benefit from outsourcing their back office tasks to external service providers so that they can focus on the main objectives and vision of the company. Thus, outsourcing back office support is a cost-effective solution for you to optimize your business operations and achieve sustainable growth.


